Data Analysis Exercise: Exploring flu vaccination coverage in U.S. adults (2020–21)
This dataset comes from the CDC’s Cumulative Influenza Vaccination Coverage for Adults 18 years and older in the United States during the 2020-21 flu season.
The surveys were done using two large national panels: the IPSOS KnowledgePanel Omnibus and the NORC AmeriSpeak Omnibus.Each row in the dataset gives us information like when the data was collected, what age or race/ethnicity group it refers to, what percent of adults said they had gotten a flu shot (the point estimate), and the confidence interval (range of uncertainty). It also shows the sample size corresponding to how many people responded that week in that group.
Load and process data:
Besides trimming the dataset to keep only the relevant columns, I also had to fix two issues. First, the Data_Collection_Midpoint_date column included unnecessary time information. Since all records for a given period already shared the same time, I formatted this column to display only the year and month (“2021 Jan”). Second, the Sample_Size column had a value labeled as “<30”, which made the variable non-numeric and broke summary calculations. To fix this, I converted all “<30” values to “30” so the column could be treated as a continuous numeric variable.
library(tidyverse)
Warning: package 'ggplot2' was built under R version 4.4.3
Warning: package 'tibble' was built under R version 4.4.3
Warning: package 'tidyr' was built under R version 4.4.3
Warning: package 'readr' was built under R version 4.4.3
Warning: package 'purrr' was built under R version 4.4.3
Warning: package 'dplyr' was built under R version 4.4.3
Warning: package 'lubridate' was built under R version 4.4.3
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.2.0 ✔ readr 2.2.0
✔ forcats 1.0.1 ✔ stringr 1.6.0
✔ ggplot2 4.0.2 ✔ tibble 3.3.1
✔ lubridate 1.9.5 ✔ tidyr 1.3.2
✔ purrr 1.2.1
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(readr)library(lubridate)library(here)
here() starts at /Users/ayllaermland/Downloads/BIOS8060E/AyllaErmland-portfolio
#Load the dataflu_data <-read_csv(here("cdcdata-exercise", "Cumulative_Influenza_Vaccination_Coverage_20260210.csv"))
Rows: 140 Columns: 18
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (8): Data_Collection_Start_Date, Data_Collection_End_Date, Data_Collecti...
dbl (8): Data_Collection_Midpoint_MMWR_Week, Data_Collection_Midpoint_MMWR_D...
num (1): Data_Collection_Midpoint_MMWR_Year
lgl (1): Suppressed
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
#Show all column names (optional)colnames(flu_data)
#Select and clean columnsflu_trimmed <- flu_data %>%select( Data_Collection_Midpoint_date, Race_Ethnicity, Age_Group, Point_Estimate, CI_Lower, CI_Upper, Sample_Size ) %>%mutate(#Format the date: "2020 Dec 19 12:00:00 AM" → "2020 Dec"Data_Collection_Midpoint_date =format(parse_date_time(Data_Collection_Midpoint_date, orders ="Y b d I:M:S p"),"%Y %b" ),#Clean Sample_Size: remove "<" if present, then convert to numericSample_Size =as.numeric(gsub("<", "", Sample_Size)) )#Save processed datasetwrite_csv(flu_trimmed, here("cdcdata-exercise", "flu_trimmed_dataset.csv"))
Exploring the data:
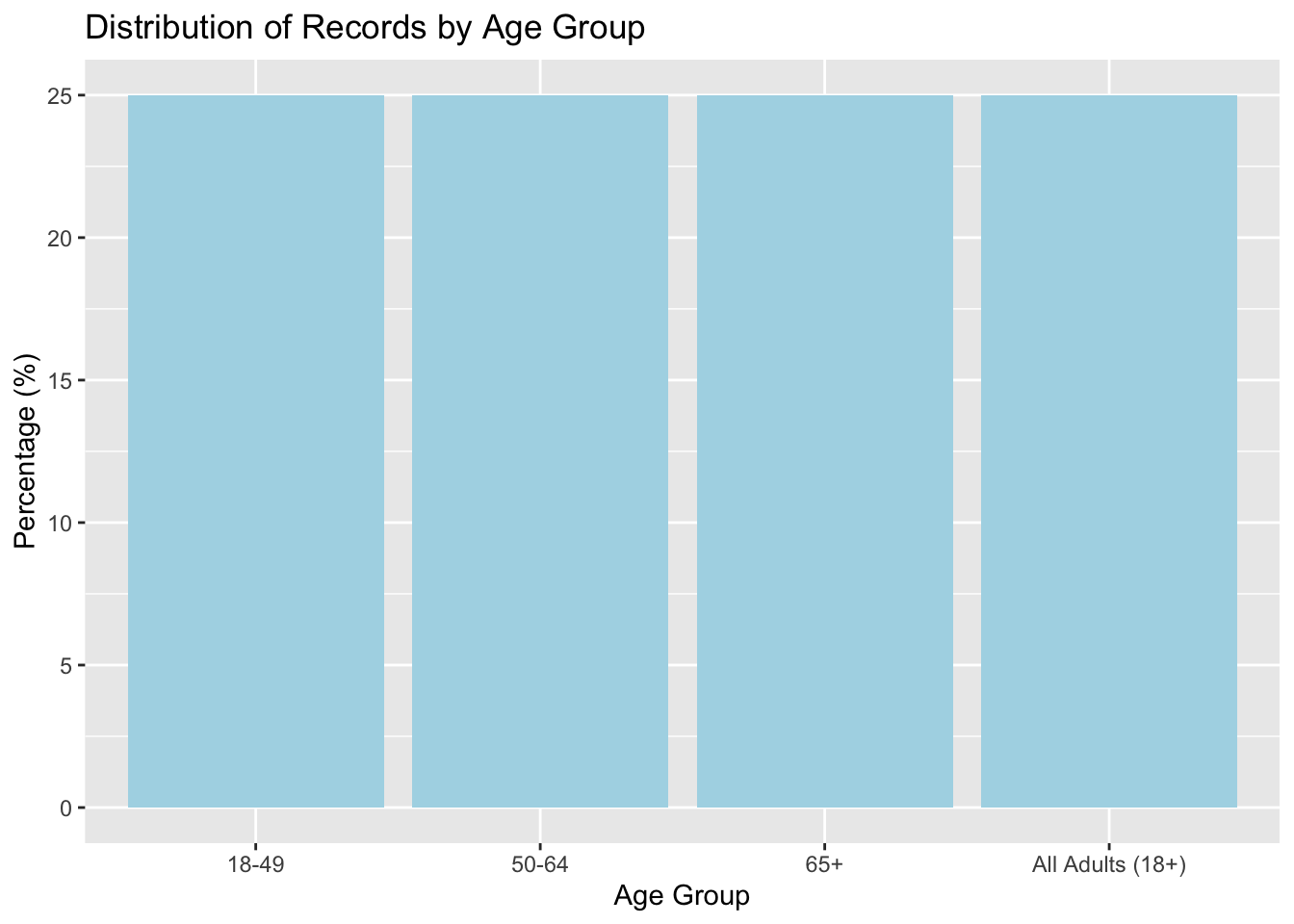
1st variable: Estimating frequencies of Age_Group variable:
#Creating a summary table for Age_Group:#This counts how many rows belong to each unique age groupage_summary <- flu_trimmed %>%group_by(Age_Group) %>%#Group the data by Age_Groupsummarise(count =n() #Count how many rows in each group ) %>%mutate(percent =round(100* count /sum(count), 1) #Calculate the percentage each group represents (rounded to 1 decimal) )#Print the summary tableage_summary
#Bar plot showing the percentage for each age groupggplot(age_summary, aes(x =reorder(Age_Group, -percent), y = percent)) +geom_col(fill ="lightblue") +labs(title ="Distribution of Records by Age Group", x ="Age Group", y ="Percentage (%)" )
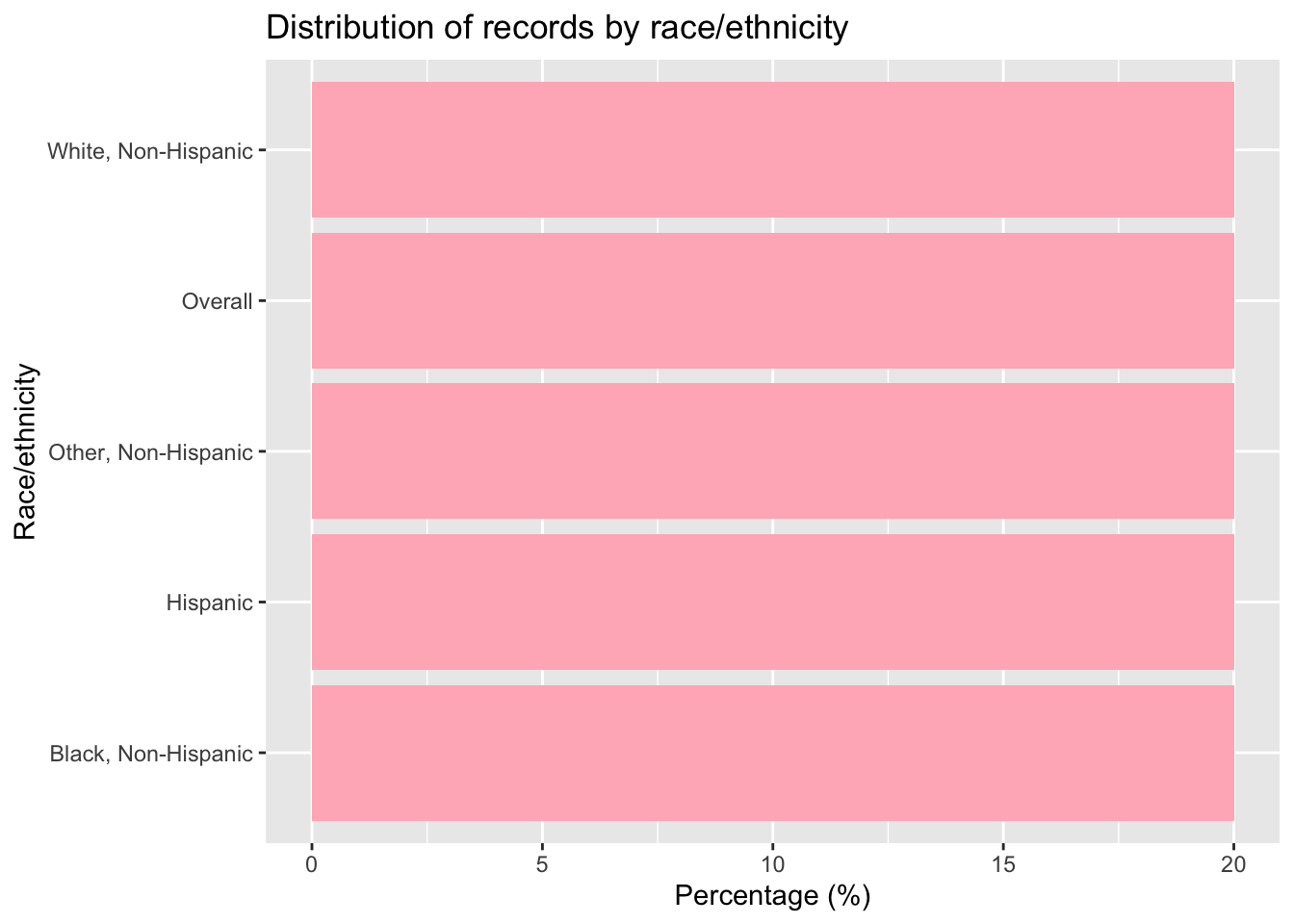
Estimating frequencies for the 2nd variable race_ethnicity:
#Creating a summary table for Race_Ethnicity:#calculates how many records fall under each racial/ethnic group and what % that israce_summary <- flu_trimmed %>%group_by(Race_Ethnicity) %>%summarise(count =n() #Count the number of records (rows) in each group ) %>%mutate(percent =round(100* count /sum(count), 1) #Calculate what % of the total each group represents )race_summary
#Bar chart of the percentage of records by Race_Ethnicityggplot(race_summary, aes(x =reorder(Race_Ethnicity, -percent), y = percent)) +geom_col(fill ="lightpink") +#Use a bar chart (column plot) with coral colorlabs(title ="Distribution of records by race/ethnicity", x ="Race/ethnicity", y ="Percentage (%)" ) +coord_flip() #Flip coordinates so bars are horizontal
3rd Variable:
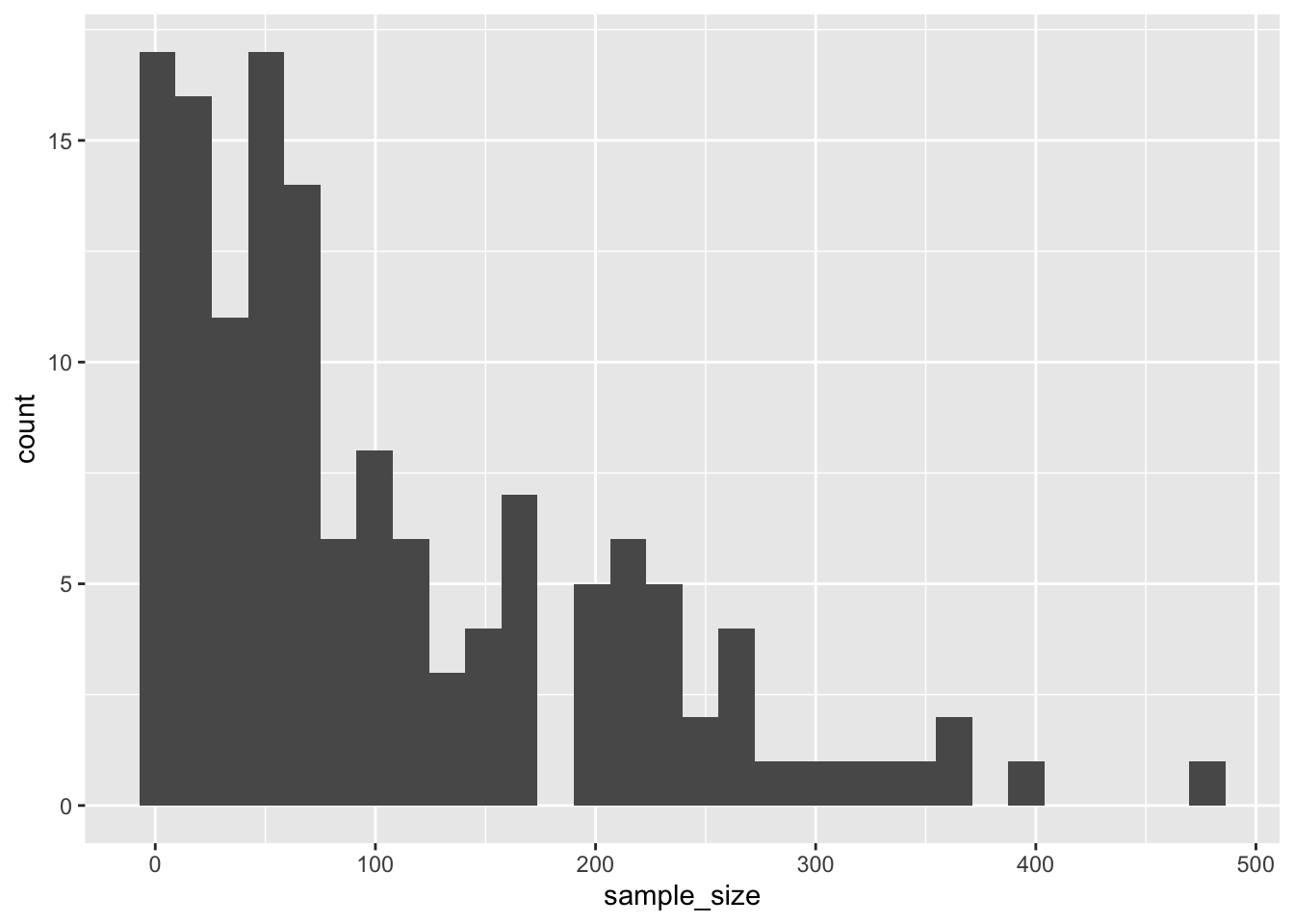
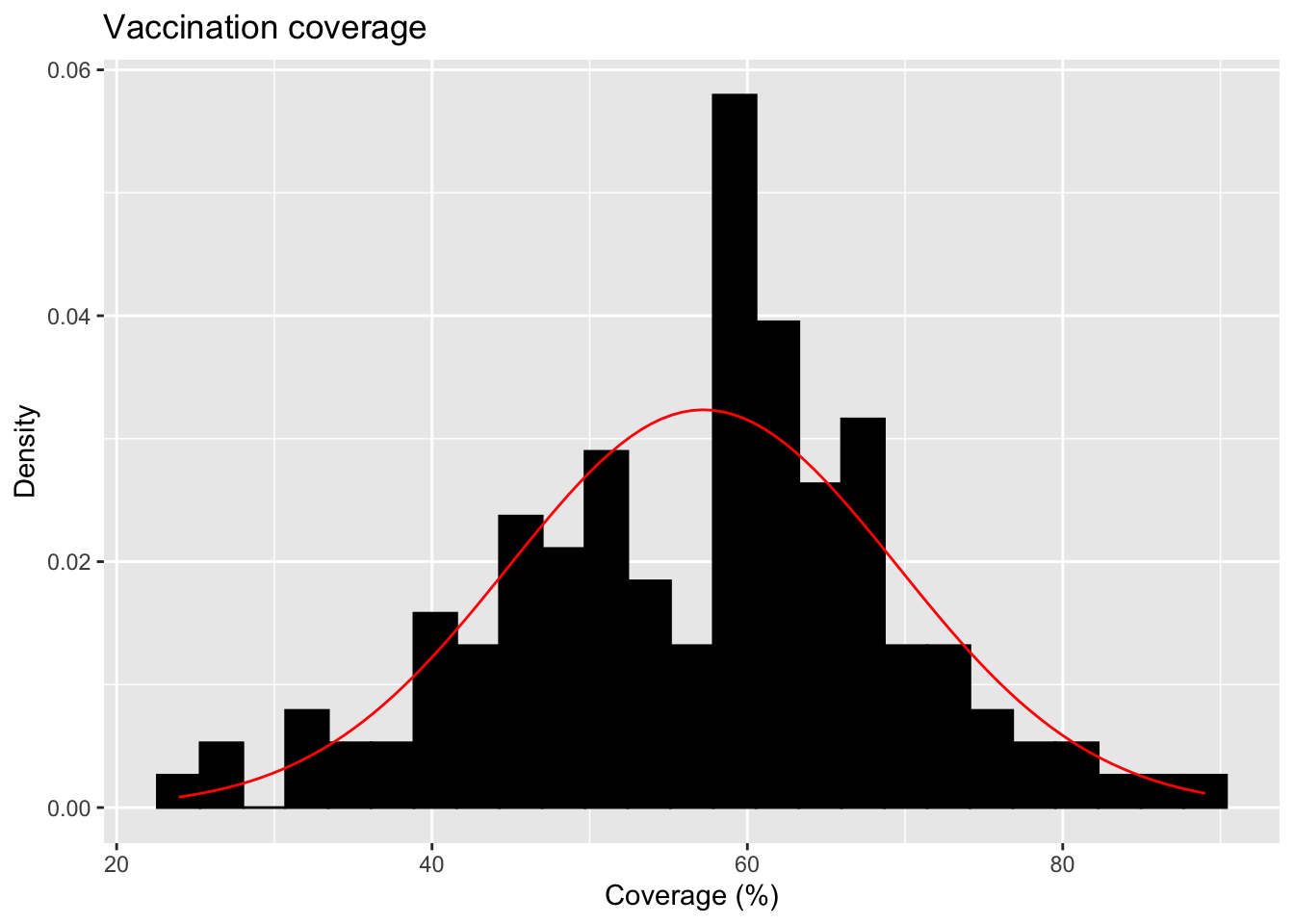
For the continuous variable of vaccination coverage, I will plot a distribution and calculate the mean and SD of this dataset.
# Histogram with normal curve (updated syntax)ggplot(flu_trimmed, aes(x = Point_Estimate)) +geom_histogram(aes(y =after_stat(density)), bins =25, fill ="black", color ="black", na.rm =TRUE) +#Add a normal distribution curve using the mean and SD from the data:stat_function(fun = dnorm,args =list(mean =mean(flu_trimmed$Point_Estimate, na.rm =TRUE),sd =sd(flu_trimmed$Point_Estimate, na.rm =TRUE) ),color ="red" ) +labs(title ="Vaccination coverage",x ="Coverage (%)",y ="Density" )
4th variable: Data_Collection_Midpoint_date
::: {.cell}
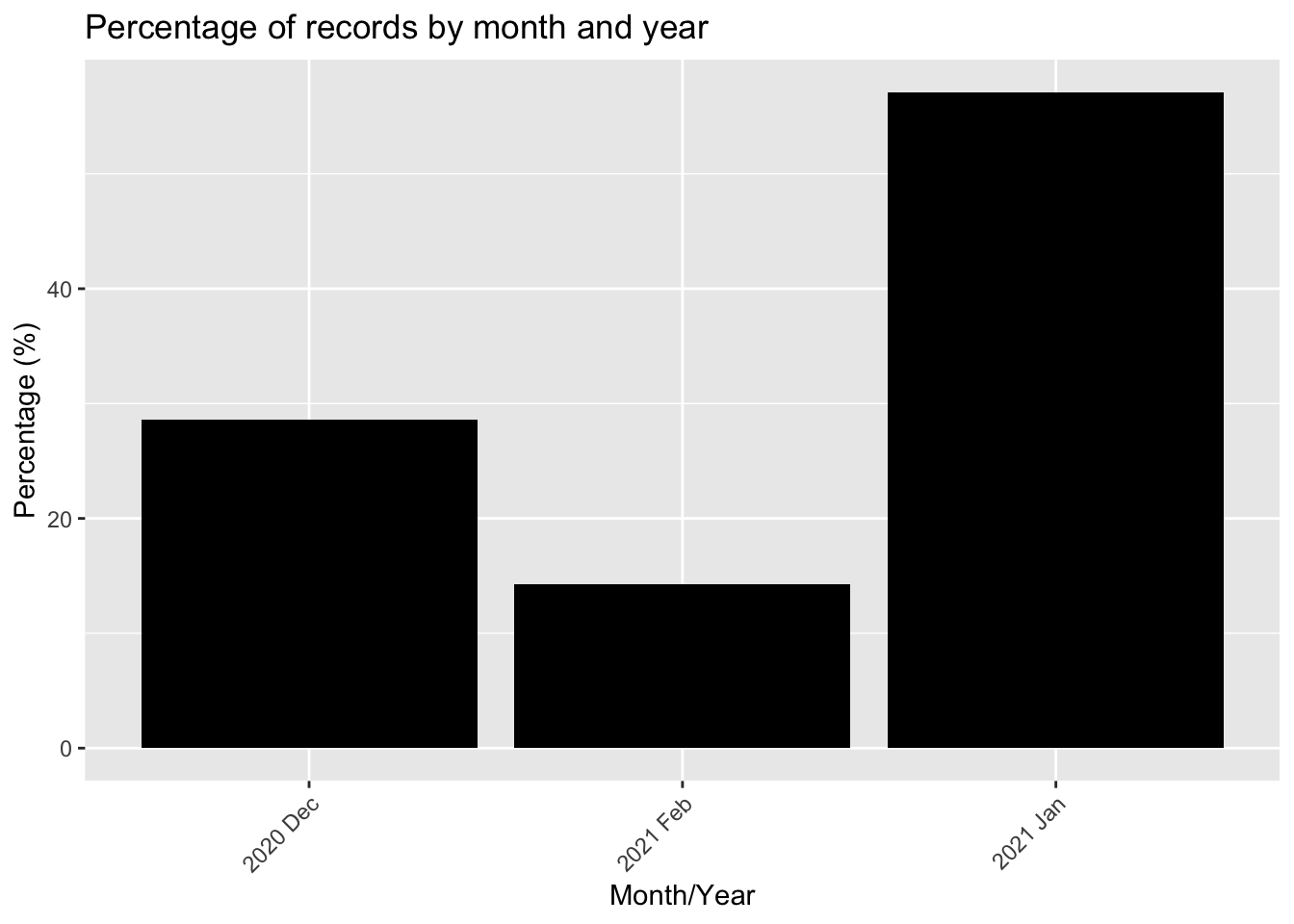
# Calculate percentage of records per monthdate_counts <- flu_trimmed %>%group_by(Data_Collection_Midpoint_date) %>%summarise(records =n()) %>%mutate(percent =round(100* records /sum(records), 1))head(date_counts) # Preview table
::: {.cell-output .cell-output-stdout}
# A tibble: 3 × 3
Data_Collection_Midpoint_date records percent
<chr> <int> <dbl>
1 2020 Dec 40 28.6
2 2021 Feb 20 14.3
3 2021 Jan 80 57.1
:::
# Bar plot showing percentage of records per monthggplot(date_counts, aes(x = Data_Collection_Midpoint_date, y = percent)) +geom_col(fill ="black") +labs(title ="Percentage of records by month and year",x ="Month/Year",y ="Percentage (%)" ) +theme(axis.text.x =element_text(angle =45, hjust =1))
::: {.cell-output-display} ::: :::
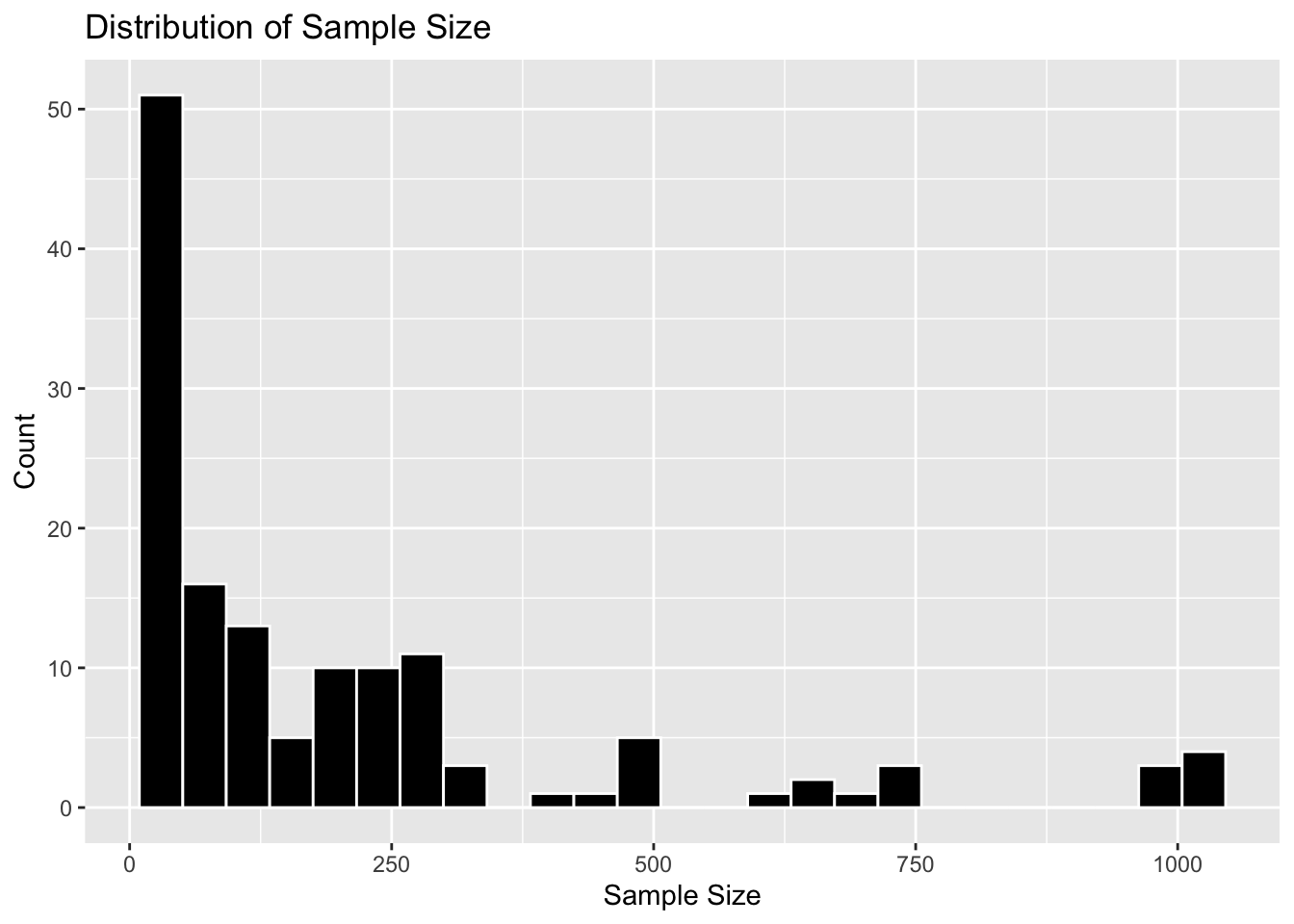
5th variable: Sample size
#Calculate mean and standard deviation for Sample_Sizesample_size_stats <- flu_trimmed %>%summarise(mean_sample_size =mean(Sample_Size, na.rm =TRUE),sd_sample_size =sd(Sample_Size, na.rm =TRUE) )sample_size_stats
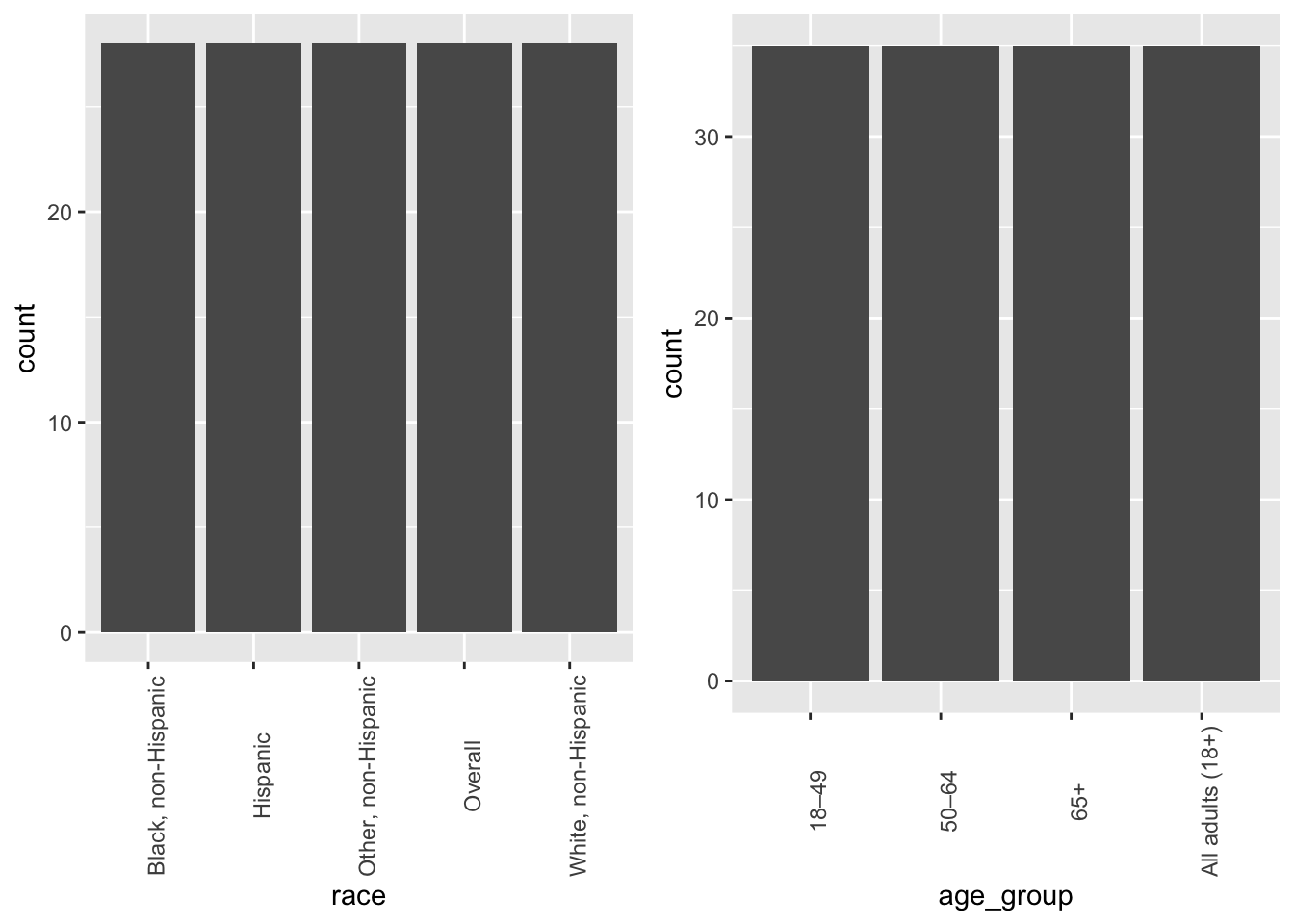
#Preparing the dataframebase_grid <-expand.grid(race = races, age_group = age_groups, stringsAsFactors =FALSE)synthetic <- base_grid[rep(seq_len(nrow(base_grid)), times =7), ]nrow(synthetic) #confirming 140 rows
[1] 140
At this point, the dataframe now has both races and age groups. Because of how they’re made, we’ve made sure that they’re equally distributed - just like in the cleaned dataset above.
The following object is masked from 'package:dplyr':
combine
grid.arrange(E1, E2, ncol =2, nrow =1)
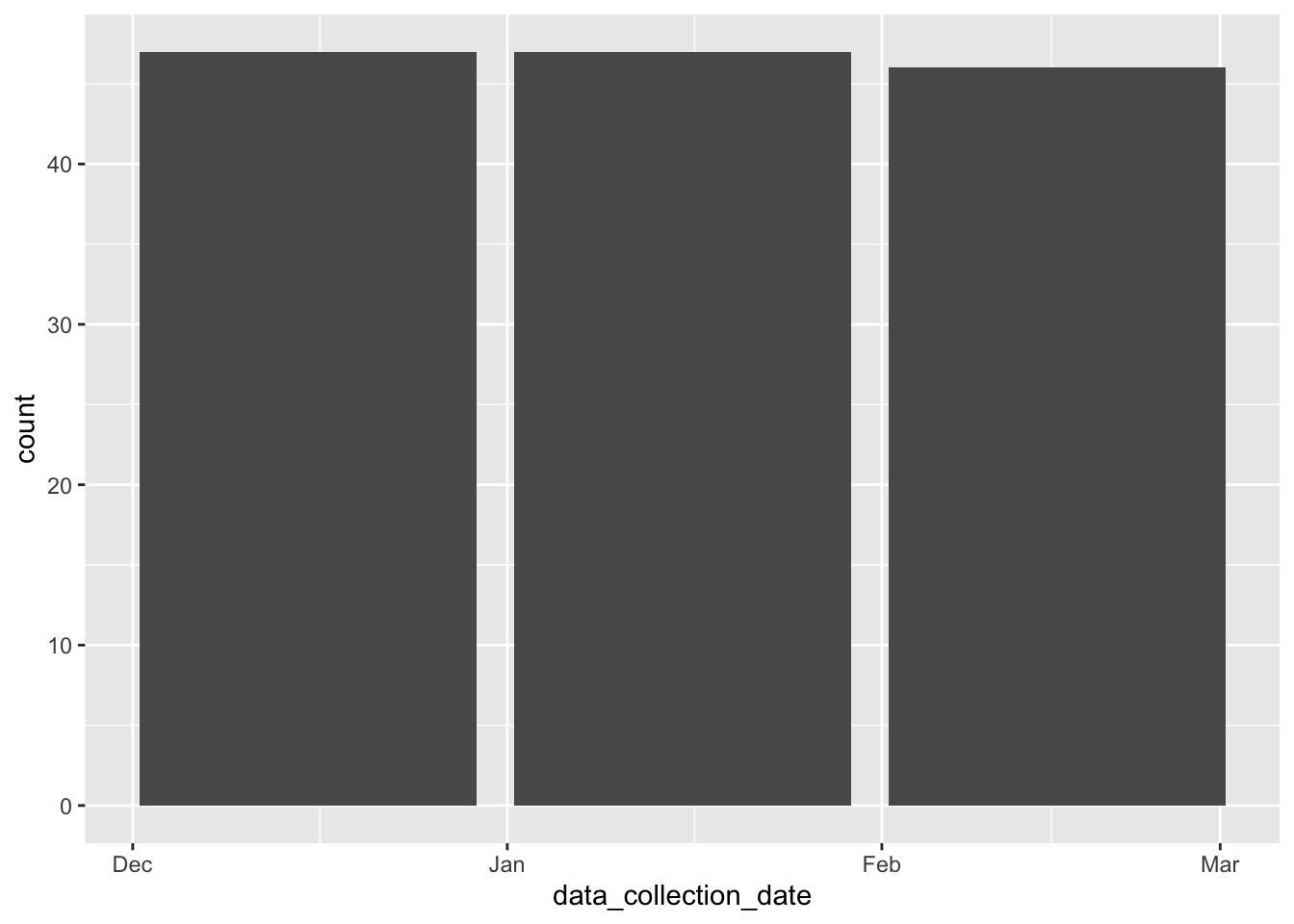
Continuing with adding more variables to the dataframe, here I’m adding dates. I only specified three entries (Dec 2020, Jan 2021, Feb 2021) but I didn’t specify the distribution. I just wanted to see what the AI would default to.
#Adding collection dates to the dataframen <-140date_vec <-rep(dates, length.out = n)date_vec <-sample(date_vec) # shuffle so dates aren’t in blockssynthetic$data_collection_date <- date_vecggplot(synthetic, aes(x = data_collection_date))+geom_bar()
The dates here are more equally distributed than the cleaned dataset above.
Next, the sample sizes. In order to recreate the distribution shape of the cleaned dataset above, I specified the prompt to produce a left-skewed distribution.
#Adding sample sizes to the data frameraw_n <-rexp(n, rate =1/120) # exponential; mean ~120 (lots of small values)sample_size <-pmin(pmax(round(raw_n), 1), 1000)synthetic$sample_size <- sample_sizeggplot(synthetic, aes(x = sample_size))+geom_histogram()
`stat_bin()` using `bins = 30`. Pick better value `binwidth`.
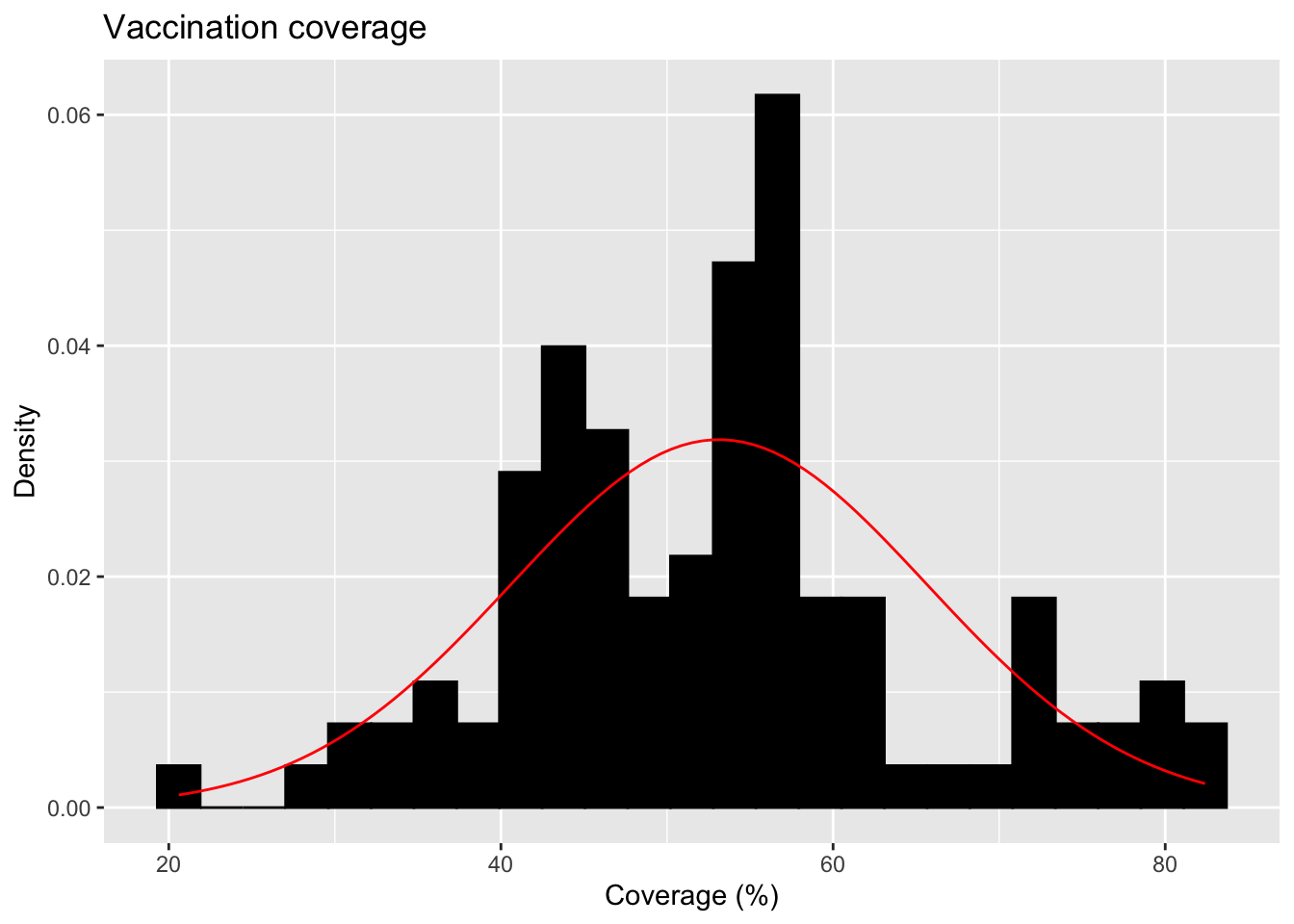
The synthetic data produced here does lean toward the left. However, I think the cleaned dataset above was way more skewed.
Lastly, vaccination coverage. I specfified the prompt that this variable should exhibit a normal distribution just like the cleaned dataset above.
#Adding vaccination coverage to the dataframecoverage <-rnorm(n, mean =55, sd =12)coverage <-pmin(pmax(coverage, 0), 100)synthetic$coverage <- coverage#Grabbing the code from above to produce the figureggplot(synthetic, aes(x = coverage)) +geom_histogram(aes(y =after_stat(density)), bins =25, fill ="black", color ="black", na.rm =TRUE) +#Add a normal distribution curve using the mean and SD from the data:stat_function(fun = dnorm,args =list(mean =mean(synthetic$coverage),sd =sd(synthetic$coverage) ),color ="red" ) +labs(title ="Vaccination coverage",x ="Coverage (%)",y ="Density" )
 ::: :::
::: :::